The Software Development Lifecycle Database
The modern software development lifecycle already produces a lot of metadata about systems, teams, changes, and failures. When you link artifacts like SBOMs, commits, deployments, incidents, and ownership data into a queryable engineering data product, you can answer cross-cutting questions about risk, support load, bottlenecks, and traceability that isolated tools struggle with. It's powerful, but only worth the effort when those questions matter often enough to justify the integration and maintenance cost.
Companies know how to treat business data as an asset. They build warehouses, pipelines, semantic layers, governance processes, and entire teams around it. That part is familiar. But when the data describes the software itself, the attitude is often very different. Suddenly, the same organization that carefully curates customer and revenue data is content with scattered and isolated information. Discussions that stretch across Jira tickets and GitHub issues, CI/CD pipeline logs that are used to determine the current deployment state, dependencies listed in a README, architecture knowledge in someone’s head, and so on.
In general, this can be perfectly fine. But it starts to bite when decisions need information that’s spread across multiple tools and teams, and in larger organizations, those decisions come up constantly. Research from the Accelerate work showed that organizations which measure engineering performance systematically tend to improve delivery capability and outcomes.1 But measuring is only half the story. If every tool offers its own isolated slice, you can optimize one local metric and completely miss the system-level consequence. A team may reduce build times while increasing deployment risk. A service may look stable while quietly becoming a central dependency for half the company.
The Questions No Single Tool Can Answer
The modern software development lifecycle already produces an enormous amount of data about itself: SBOMs2, CVEs3, commits, tickets, CI results, runtime metrics, architecture diagrams, postmortems, alerts, deployments, ownership mappings. Each tool answers its own question reasonably well. But the intricate engineering questions don’t respect those tool boundaries.
Some of these are analytical questions that shape long-term decisions:
- Which part of the software generates the highest support burden over time?
- Which applications are affected by a vulnerability directly or transitively, and how critical is that impact really?
- Where are the technical and organizational bottlenecks in the architecture?
- How are change-risk, resilience, and architecture erosion developing over the last year?
Others are operational questions that help you decide what to do right now:
- Who needs to be involved when a shared internal capability changes?
- Which team should react first to this incident?
- Which deployment is the most likely trigger for the behavior we’re seeing?
- What is the current state of this particular feature of our service?
You can answer pieces of these today. An SBOM can tell you that a package is present. A ticket system can tell you that a customer problem was reported. Your deployment system can tell you which version is currently running. But to gain a deep understanding of the landscape, we have to look at the relationships between these pieces of information. And answering it today usually means stitching exports together, chasing Slack threads, opening four tabs, and relying on whoever happens to remember the last migration. That’s fine occasionally. It doesn’t scale as a normal operating model.
From Artifacts To Linked Knowledge
So what do you do about it? One useful framing: treat your engineering artifacts and the relationships between them as a data product. Not every log line dumped into a grand platform. A selected set of engineering entities and relationships, collected, versioned, enriched, governed, and made queryable in a form that other teams can reliably use. A deliberate body of linked engineering knowledge.
From artifacts to linked engineering knowledgeThe data-product mindset is what makes that structure durable enough to trust. It means treating this knowledge with the same rigor you’d apply to a customer-facing data product: clear ownership, defined quality standards, deliberate governance. For the rest of this post, we’ll call the concrete realization of that data product the Software Development Lifecycle Database (SDLC DB): a queryable, governed representation of your engineering landscape. What follows is one concrete way to build it.
Building The Data Product
There are many ways to turn that idea into something real: a graph database, a relational store with well-designed joins, a data lake feeding derived views, or some combination. For our case, the questions we care about most (transitive dependency chains, impact radius, ownership paths) are naturally expressed as graph traversals, so we’ll use a graph database (Neo4j, Amazon Neptune, or a PostgreSQL graph extension like Apache AGE are common choices) as the core. On top of that, we’ll build the central model and the data pipelines that feed it. This certainly isn’t the only way to build such a data product, but it illustrates the core idea and makes it tangible.
Designing The Model
Graphs consist of nodes and edges, but what makes a node in our model? What makes an edge? What values and metadata should they carry? Modeling this structure means building up knowledge of the landscape and organizational structures first. Then it’s time to structure that knowledge in a way that helps you answer relevant and intricate questions easily, without limiting you to only those questions. The goal is a general-purpose model that can answer many questions.
A good heuristic for what becomes a node: if multiple other things need to reference it, and you’d want to query it independently, it’s a node. A service is a node because deployments point to it, teams own it, incidents impact it, and dependencies attach to it. You’d ask “show me everything about checkout-service,” and the answer comes from following all those connections. A version string like 3.0.x doesn’t have that property: nothing else in the graph references it independently, so it lives as a property on the dependency node instead.
Edges deserve the same care. A “depends on” relationship between a service and a library might include the version range, the scope (compile vs. runtime), and whether it was extracted from an SBOM or inferred from import statements. Temporal validity (when did this start? is it still active?) and confidence (asserted from an authoritative source, or inferred from signals?) are first-class concerns from day one. Direction matters too: Team -> owns -> Service makes it easy to find everything a team is responsible for, but answering “who owns this service?” means traversing that edge in reverse. Which direction you choose shapes which queries are natural and which require extra work.
Here’s what that web of nodes and edges could look like when you put it all together:
Example graph of interconnected software artifactsThe model’s power comes from the paths you can walk through it. Each path maps to a question no single tool can answer on its own:
Service -> depends on -> Library -> vulnerable to -> CVE: which services are affected by this vulnerability, directly or transitively?Person -> member of -> Team -> owns -> Service: who needs to know about this incident?Commit -> triggers -> Build -> promotes -> Deploy -> to -> Environment: what’s running in prod right now?Ticket -> implemented by -> Commit -> triggers -> Build: has this fix been deployed yet?
That’s the conceptual side: what to model and why. Once you start putting this into practice, a few technical challenges show up in every implementation:
Unique identifiers across tools are a tricky problem you have to solve early. How do you connect a Jira project to a GitHub repository to a runtime service? There’s rarely a natural shared key. You end up defining synthetic identifiers or mapping tables, and that mapping logic becomes one of the most critical (and most fragile) pieces of the entire system.
Granularity shapes what questions you can answer. Should every Jira ticket become its own node, or is a single project-level node with a ticket count enough? Should you model each version of a library separately, or just track the latest? There’s no universal answer. If you need to trace a specific change back to a specific ticket, you need ticket-level nodes. If you only care about velocity trends, an aggregate might do. Getting this wrong has real consequences. If you model “Service B” as a single node, you lose the fact that Service A depends on v2.3.4 while Service C depends on v2.4.5. If v2.3.4 goes down, a coarse model flags both consumers. Notifying Service C’s team about a problem they don’t have doesn’t just create noise, it damages the credibility of the entire model. You might need version-specific nodes, or at least version-qualified edges, to keep the answers precise enough to act on.
Nuances during modelingEntity boundaries need to be consistent, and the one with the most impact is usually the service. Is a “service” just the backend process, or the entire stack including its frontend, database, and message consumers? Different organizations draw that line differently. Whatever you decide, it has to be consistent across the model, because the service is the anchor point that most other relationships attach to.
Stable identity and edge confidence matter as soon as things change. A service needs a stable identity even if the repository gets renamed. A team shouldn’t disappear from history just because the org chart changed. A dependency edge may need a timestamp or validity interval if you want to ask what the world looked like last month. And some links are asserted because they come from an authoritative source (a catalog saying team Platform-Payments owns service checkout-api), while others are only inferred (guessing ownership from commit history or Slack channels). Both can be useful, but they shouldn’t pretend to be the same kind of fact.
The one idea to keep at the center while designing the model: think about the questions you want answers for. Don’t think about the technical implementation. Don’t think about where the data has to come from. Focus on the look and feel of your model. Which parts connect to which others, which information belongs where. Only after that picture has materialized does it make sense to move on to the technical part. And so will we.
Ingestion And Preprocessing
Data ingestion and preprocessingTo feed the Model we need data. The raw material comes from systems you already have: source control, ticket trackers, CI/CD pipelines, artifact registries, observability platforms, identity providers, and internal catalogs. Each system sees its own slice of reality. Your job is to decide which pieces are worth lifting into the shared model, and to build ETL pipelines that extract, normalize, and load them. Standard data engineering: normalize identifiers, deduplicate records, resolve identities, enrich with classifications, preserve history. Let’s look at a few concrete examples to get a feeling for the kind of data we’re dealing with:
Connecting tickets to features. If you can’t trace a customer problem or a compliance requirement back to the code that implements it, questions like “has this been fixed?” or “which services fulfill this requirement?” stay unanswerable. There are two approaches here. The first is to enforce a convention where developers tag every commit with a ticket number (you can even enforce this in the pipeline with a commit-message hook). The second is to use fuzzy search or, better yet, an LLM to map code changes to ticket requirements after the fact. Either way, you can then extract tickets from a Jira project and link them to the commits, pull requests, and services they actually touched.
Static dependencies between Java applications. Without knowing which libraries and versions each service actually uses, you can’t answer questions about vulnerability exposure or transitive risk. One efficient approach is to add a job to the CI/CD pipeline that runs every time an application is deployed to a relevant environment. The job reads pom.xml, extracts the Maven dependency tree (Maven has a built-in command for that), and a small helper script connects to the SDLC DB to create or update the corresponding nodes and edges. Because it’s triggered by the pipeline itself, the data stays close to real time without any separate polling infrastructure.
Dynamic runtime dependencies via Service Mesh. Some dependencies simply can’t be resolved from static code. Dynamic HTTP calls to REST endpoints are a common example: the URL is often stitched together at runtime from configuration, environment variables, or even database lookups. No amount of source analysis will reliably extract those. If you’re running a service mesh, the control plane already knows which service actually communicates with which other service at runtime. You can extract that communication graph from the mesh and push it into the SDLC DB, giving you a view of real dependencies that static analysis would miss entirely.
Live system state via Prometheus alerts. A structural map alone can’t tell you whether a service is healthy right now. Without live signals, operational questions (“which services are currently degraded?”, “is this deployment causing problems?”) require switching to a different tool. Prometheus has a comprehensive alerting system. You can use it to track health signals, critical resource consumption, or SLO breaches and write those values into the database as properties on the corresponding service nodes.
As the number of these pipelines grows, managing them individually becomes painful. Tools like Apache NiFi, Apache Airflow, or Argo Workflows can help orchestrate them at scale. With an orchestration layer in place, the data sources only need to provide a minimal trigger point (for example, a CI/CD job calling a webhook). The rest of the extraction, transformation, and loading is handled by the pipeline definition in the orchestrator.
Example of a data pipeline“Just ingest everything” is usually a mistake. If you don’t know which entities and edges matter, you end up warehousing noise. Better to start with a smaller set of high-value integrations and make the links reliable than to build a giant metadata lake nobody trusts.
Lifecycle And Decay
Once data is flowing into the model, a new problem appears: decay. If the model reflects a near-real-time view of the landscape, it will naturally accumulate stale entries: dependencies that no longer exist, services that were shut down, teams that merged. If you never clean that up, the data becomes slower, noisier, and harder to trust. Garbage collection becomes part of the architecture: removing orphaned records, expiring obsolete relationships, archiving retired entities, or moving old snapshots into a separate historical store.
That leads to a core design choice: what do you preserve as history, and what do you only need as current state? If you mostly keep the current landscape, operational queries stay fast and the system stays lean. If you keep everything, you can reconstruct historical events, analyze long-term change patterns, and evaluate architectural evolution. But that richer history costs storage, modeling effort, and query complexity.
Putting It All Together
With a storage strategy, a model, ingestion pipelines, and a lifecycle approach in place, here’s what the complete system looks like:
A complete Software Development Lifecycle DatabaseFour parts make up the system. The raw material comes from the tools your organization already runs: source control (GitHub, GitLab), ticket trackers (Jira), CI/CD systems (Jenkins, ArgoCD), runtime infrastructure (Kubernetes, Prometheus), identity providers (Active Directory), and whatever else captures facts about your landscape. Data pipelines act as processors: they normalize, deduplicate, enrich, and link that raw material into canonical entities and relationships. The central database (the SDLC DB) stores the result as a queryable, governed model. And a garbage collector keeps it honest by expiring stale edges, archiving retired entities, and preventing the model from silently drifting away from reality. None of the individual pieces are particularly exotic. The value comes from connecting them into a coherent whole: a single maintained representation of your engineering landscape that multiple tools and teams can query and build on.
What You Can Build On Top
The value doesn’t stop with answering questions directly. The software development lifecycle database becomes a foundation for internal engineering products.
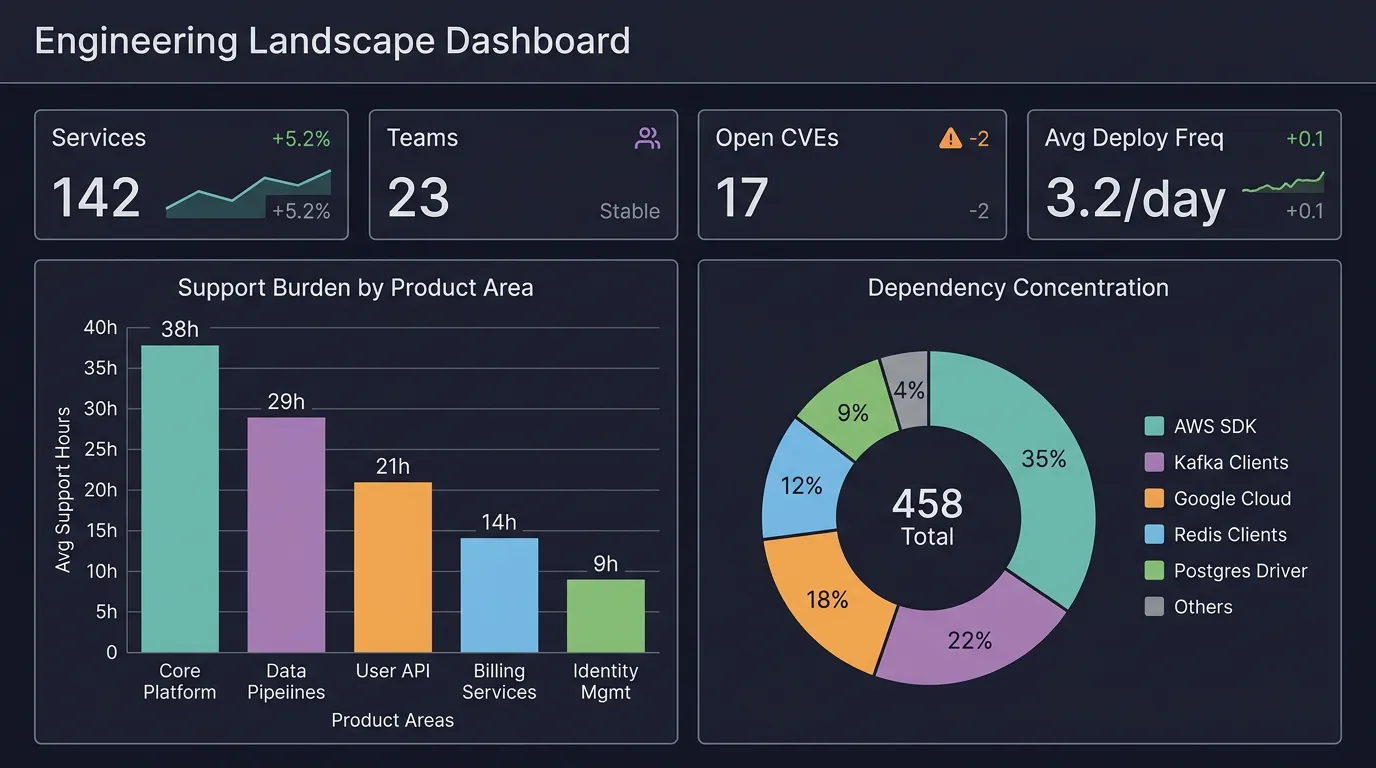
Building on top of the Software Development Lifecycle DatabaseThe obvious first layer is BI reporting and dashboards. Think support burden by product area, dependency concentration across the landscape, change-risk indicators over time, incident hotspots by team or service tier. Tools like Grafana can pull live data from the engineering database and visualize it alongside runtime metrics, giving leadership and engineering managers a single view that connects code-level changes to business-level impact. Useful, but only the beginning.
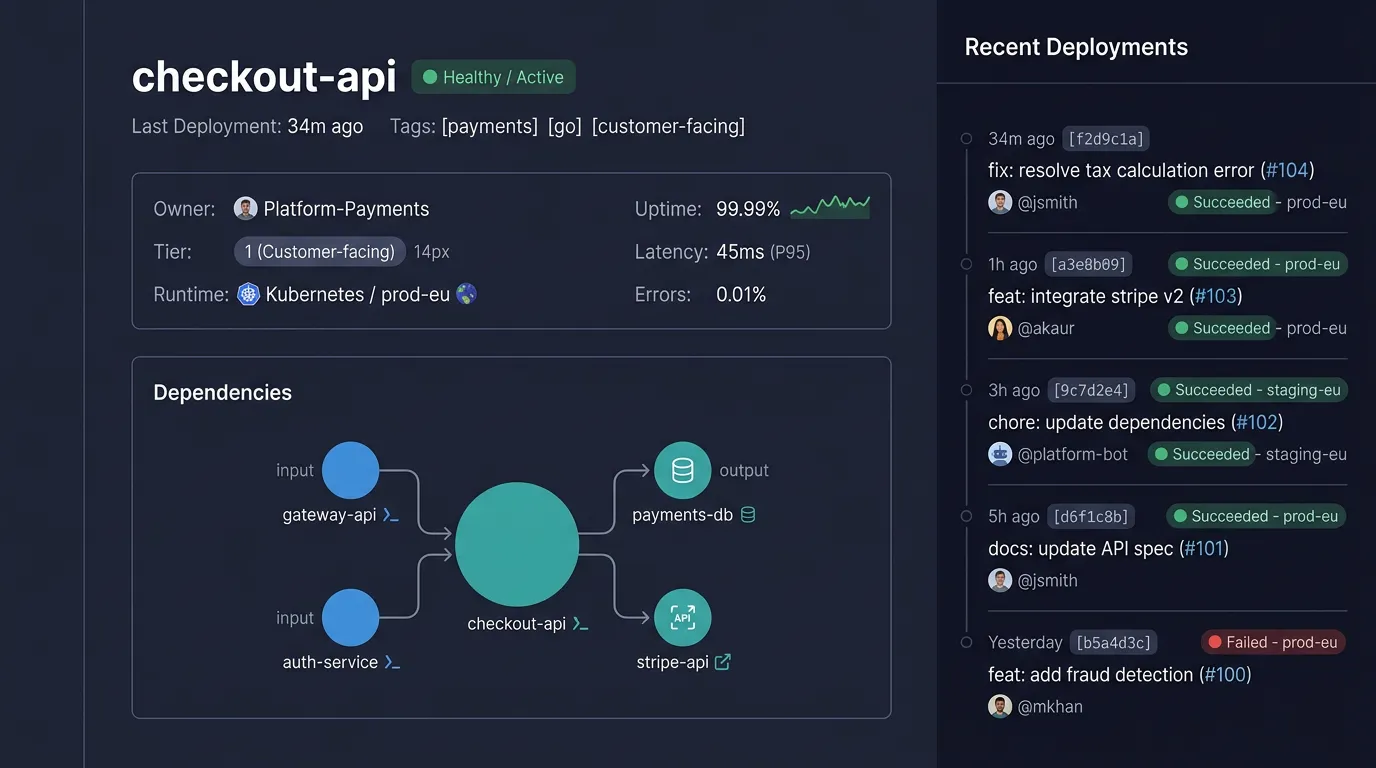
The more interesting possibility is a context-aware developer platform. Tools like Backstage, Cortex, or OpsLevel already provide the portal and catalog layer. The SDLC DB can serve as a data backbone that feeds them with richer context than any single source could provide. Imagine a developer opening a service page and immediately seeing not just the README, but the full picture: who owns this service, what it depends on, which teams are affected if it changes, what its deployment history looks like, whether it has open vulnerabilities, and how it fits into the broader product architecture. Instead of hunting through four different tools, the platform assembles that context from the engineering database. It can pre-fill rollout checklists based on actual downstream dependencies, flag missing operational metadata before a deploy, and surface golden-path recommendations that reflect how the system really works rather than how someone once documented it.
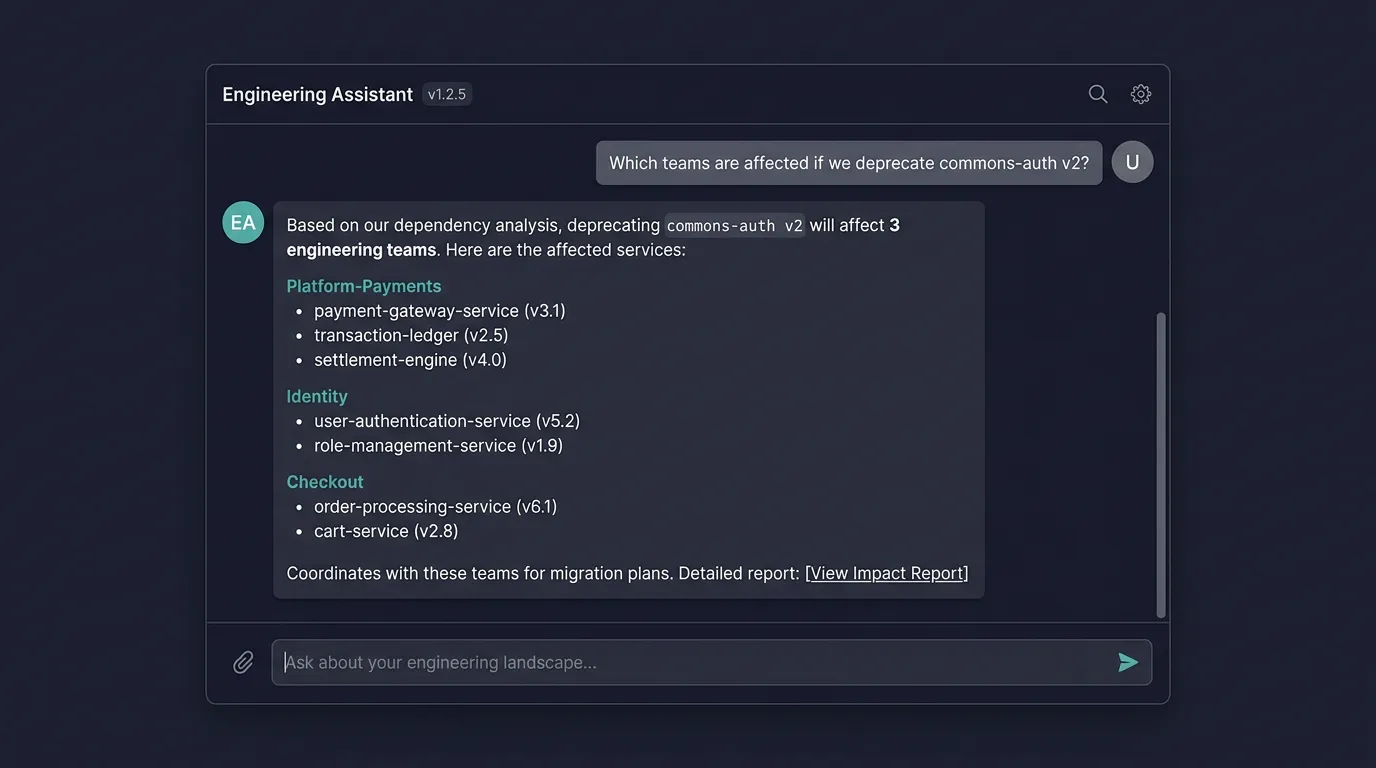
A conversational interface is another natural fit. Connect an LLM via tool calls that query the database, and engineers can ask questions like “Which teams are affected if we deprecate library X?” directly. The database provides the structured facts, the LLM provides the natural-language layer.
You can imagine similar layers for security operations, architecture governance, support tooling, or incident response. The same underlying data product can power reports for leadership, risk views for security, and context-aware workflows for engineers.
Is It Worth It?
A system like this isn’t free. Not every organization needs it.
If you’re working with a handful of services, stable ownership, and direct communication paths, a few dashboards and good conventions will carry you far. The SDLC DB becomes worth the investment when fragmented knowledge is a recurring pain: many teams, many services, shared platforms, strong compliance requirements, and coordination costs that keep showing up. If those questions come up constantly and answering them still feels like a manual investigation every time, this stops being overengineering.
And it can’t realistically be treated as a side project. Designing, building, and maintaining the ingestion pipelines alone consumes real engineering capacity. If the organization wants the result to be trustworthy, durable, and reusable, it has to fund it like an internal product rather than a clever experiment.
The hard part isn’t the storage engine. It’s data quality, ownership, preprocessing, and maintenance discipline. Who defines what a service is? What counts as ownership? How do relationships get updated when teams change, repositories split, or infrastructure moves? If those questions are ignored, the platform quickly becomes a confidence trap: impressive enough to demo, unreliable enough to avoid. A data product without stewardship is just a nicer-shaped data swamp.
There’s also a non-technical boundary that matters. In some countries, including where I live (Germany), you have to be careful what you store, how long you store it, and what kinds of conclusions you derive from it, especially once the data can be used to evaluate individuals. A platform designed to understand engineering systems can easily drift into employee monitoring if governance is weak. That isn’t only ethically questionable, it may also be legally restricted. The model needs privacy, labor-law, and governance boundaries from the start.
This post showed you the end goal, the Ferrari. You probably don’t need all of it from day one. Maybe you never will. Start with a few high-value connections and expand from there as the questions demand it.
Considering all these challenges, at some point, the cost of not connecting the dots outweighs the cost of building the wiring.
Footnotes
-
Nicole Forsgren, Jez Humble, and Gene Kim, Accelerate: The Science of Lean Software and DevOps (IT Revolution, 2018). ↩
-
An Software Bill of Materials (SBOM) is a formal, machine-readable inventory that details all the components, libraries, and dependencies used to build a specific piece of software, acting like an ingredient list to help organizations track supply chain risks and vulnerabilities. ↩
-
A Common Vulnerabilities and Exposures (CVE) is a standardized identifier for a specific, publicly disclosed cybersecurity flaw in a software or hardware product, allowing security professionals to track and patch the same issue across different tools and databases. ↩